

20 feb Penguin in 2023
De introductie van Penguin
Op 24 april 2012 lanceerde Google het webspam-algoritme-update genaamd Penguin om gemanipuleerde backlinks te herkennen. Dit algoritme werd later bekend via een tweet van Matt Cutts, die toen hoofd was van het webspam-team. Het behoort sinds 2016 tot hun kernalgoritme. De kracht zit hem er in dat dit algoritme werkzaam is in alle talen en een lijst opstelt met websites met gemanipuleerde backlinks. Met de laatste update is Google nu nog sneller in staat dit werk te doen. Waar vroeger meer de focus lag op het aantal links, ligt tegenwoordig steeds meer de focus op de relevantie (kwaliteit) van de links. Dit kon als resultaat hebben dat sommige website van lage kwaliteit toch hoge positionering kregen wat Google natuurlijk een doorn in het oog was.
Penquin werkt vandaag granulair, wat betekent dat de links zelf voornamelijk al SPAM worden geïdentificeerd en niet per se de ranking van de website aanpast. Dit was in het verleden wel zo. De conclusie die we snel hieruit kunnen trekken is dat slechte backlinks vandaag de dag geen nekel toegevoegde waarde hebben, maar dus niet per sé van invloed zijn op je positie in de organische resultaten. Al is wel aannemelijk dat wanneer een website excessief veel SPAM-achtige backlinks heeft dit wel schadelijk zal zijn als hier over een langere periode geen actie op wordt ondernomen.
Penquin moet een element zijn wat serieus dient te worden genomen, echter is het maar 1 van de meer dan 200 signalen die de ranking in Google bepalen. Google zelf heeft maar al te vaak aangegeven: ‘Concentreer je op het maken van relevante en goede websites’ en impliceert hiermee dat dit voldoende zou moeten zijn om goede resultaten te behalen. Ik ben het hier deels mee eens, want het op de hoogte zijn van onderdelen van het algoritme maakt dat je ook rekening kan houden met de technische kant waardoor er per vergissing gemaakte fouten kunnen worden voorkomen. Soms is de eigenaar van een website helemaal niet verantwoordelijk voor slechte backlinks maar weet ook niet dat deze mogelijk schadelijk zijn. Door hier kennis van te hebben en weten hoe ze onschadelijk te maken voorkom je penalty’s van Google.
Waarschuwing in Search Console
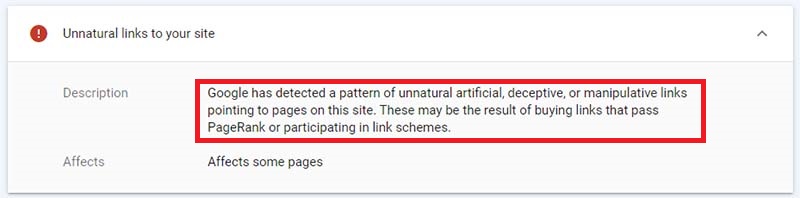
In Search Console zal Google een waarschuwing geven wanneer er “onnatuurlijke” backlinks zijn aangetroffen. Deze melding negeren is zeer onverstandig, Google waarschuwt tenslotte niet voor niets. Google beweert dus voornamelijk links van slechte kwaliteit te negeren, maar is dus wel degelijk alert en blijf iedere website crawlen op onnatuurlijke patronen zoals linkschema’s, PBN’s (Private Blog Networks), linkuitwisselingen en onnatuurlijke patronen. Het voornaamste doel van het algoritme is om blackhat-spamtechnieken te herkennen. Door het type backlinks die websites ontvangen beter te begrijpen en te verwerken, zorgt dit er in de praktijk voor dat website met natuurlijke, relevante links van autoritaire website worden beloond en manipulatieve, spamlinks worden genegeerd. Penguin houdt zich alleen bezig met de backlinks van een site en niet naar de uitgaande links.
Google’s SPAM Policy
Het spambeleid van Google is in het leven geroepen om gebruikers te beschermen en de kwaliteit van zoekresultaten te verbeteren. Voor een goede positionering in hun zoekmachine moet alle content op een website (pagina’s, afbeeldingen, video’s, nieuwsberichten, etc.) in overeenstemming zijn met het algemene beleid van Google Zoeken. Dit beleid is binnen Google van toepassing op alle zoekresultaten, inclusief Google Ads, YouTube, Discovery Network en andere kanalen. Het Penquin-algorimte detecteert content en ontwikkelingen en kan zelfs leiden tot beoordelingen van werknemers binnen Google. Bij websites die hun beleid schenden kan die werknemer overgaan tot handmatige actie wat leidt tot lagere ranking in de SERP’s (Search Engine Result Page) of zelfs een totale verbanning.
Cloaking
Cloaking verwijst naar de praktijk van het presenteren van verschillende content aan bezoekers en zoekmachines met de bedoeling om de zoekresultaten te manipuleren en gebruikers te misleiden. Voorbeelden van cloaking zijn:
• Een pagina over hotelovernachtingen weergeven aan zoekmachines terwijl een pagina over drugs wordt weergegeven aan bezoekers
• Alleen tekst of zoekwoorden automatisch in een pagina invoegen wanneer een zoekmachine langskomt en deze weglaten bij een menselijke bezoeker
Als jouw site technieken gebruikt die ertoe leiden dat zoekmachines moeilijk toegang hebben tot jouw content moet je er voor zorgen dat dit ongedaan wordt gemaakt. Als jouw website wordt gehackt, komt het vaak voor dat de hacker cloaking gebruikt om de hack moeilijker herkenbaar te maken, dus het voorkomen hiervan is essentieel.
Doorways
Doorways zijn websites of pagina’s die speciaal zijn gemaakt om te rangschikken voor specifieke, vergelijkbare zoekopdrachten. Ze leiden gebruikers naar tussenliggende pagina’s die verder geen enkele toegevoegde waarde hebben voor bezoekers.
Voorbeelden van doorways zijn:
• Meerdere websites hebben met kleine wijzigingen op de URL’s en homepage om zo veel mogelijk verkeer te trekken op dat ene zoekwoord
• Meerdere domeinnamen of webpagina’s die speciaal zijn gemaakt om bezoekers in specifieke regio’s of steden naar een pagina te leiden
• Pagina’s die zijn ontworpen om bezoekers rechtstreeks naar een bepaald deel van de website te leiden
• Duplicaat pagina’s die speciaal zijn ontworpen om te scoren op keywords en hierdoor onnatuurlijk zijn
Gehackte content
Met gehackte content wordt verstaan alle content die zonder toestemming op een site wordt geplaatst doordat de veiligheid van de website niet op orde is. Gehackte content leitd tot slechte zoekresultaten voor bezoekers van Google en kan zelfs mogelijk schadelijke software op hun apparaat installeren. Voorbeelden van hacken zijn:
• Code injection: wanneer hackers toegang hebben tot jouw website, kunnen ze schadelijke codes plaatsen in bestaande pagina’s op jouw site. Dit zijn vaak malafide types JavaScript dat rechtstreeks in de site of in het frame wordt geplaatst.
• Pagina injection: soms kunnen hackers zelfs vanwege ondeugdelijke beveiliging compleet nieuwe pagina’s aan jouw website toevoegen die spam of andere schadelijke zaken bevatten. Deze pagina’s zijn vaak ontworpen om zoekmachines te misleiden of in ergere gevallen is er sprake van phishing. Jouw bestaande pagina’s vertonen mogelijk geen enkel teken van hacking, maar deze verborgen pagina’s kunnen de bezoekers van jouw website schade toebrengen en dit leidt onherroepelijk tot stevige penalty’s van Google.
• Content injection: het is voor hackers ook mogelijk bestaande pagina’s op jouw website subtiel te manipuleren. Het doel is om content aan jouw website toe te voegen die zoekmachines kunnen zien, maar die voor een bezoeker onzichtbaar zijn. Dit kunnen verborgen links of verborgen stukken tekst zijn.
• Redirects: Hackers kunnen ook schadelijke redirects (omleidingen) maken die bezoekers omleiden naar schadelijke of spamachtige pagina’s. Het soort omleiding is soms afhankelijk van de hacker, user agent of apparaat. Het bekendste voorbeeld is dat je na op het klikken van een URL in de zoekresultaten van Google wordt doorgeleid naar een verdachte pagina maar dit niet gebeurt wanneer de url rechtstreeks wordt ingetypt.
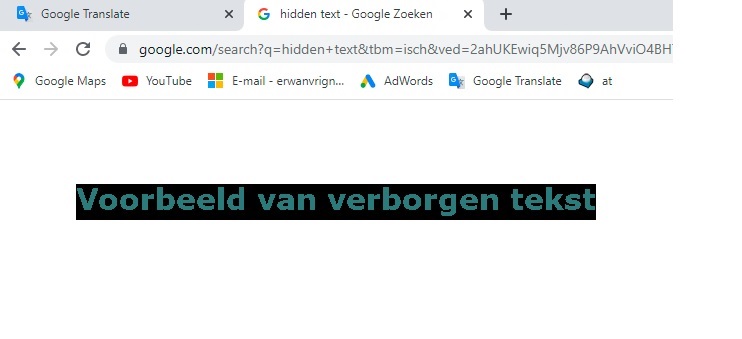
Verborgen tekst en links
Verborgen tekst en/of links is content die zo is ontworpen dat ze niet zichtbaar zijn voor bezoekers maar wel voor zoekmachines. Voorbeelden van verborgen tekst of links zijn:
• Witte tekst gebruiken op een witte achtergrond
• Tekst verbergen achter een afbeelding
• CSS gebruiken om tekst buiten het scherm te plaatsen
• De tekengrootte instellen op 0
• Een link verbergen door slechts één klein teken te hyperlinken (bijvoorbeeld een link toewijzen aan een “.” aan het einde van een zin.)
Er zijn ook elementen die verbergen van content op een dynamische manier gebruiken om de UX (User Experience) te verbeteren, dit is niet in strijd met het beleid van Google:
• Content met accordeons of met tabbladen die schakelen tussen weergeven of verbergen van extra content
• Diavoorstellingen of een schuifregelaar die verschillende afbeeldingen weergeeft
• Elementen die extra inhoud weergeven wanneer gebruikers interactie hebben met een button of conversievenster
• Tekst die alleen zichtbaar is voor bezoekers bij bepaalde relevante handelingen en dan pas wordt vertoond
Keyword Stuffing
Met keyword stuffing wordt bedoeld het vullen van een webpagina met onnatuurlijk veel zoekwoorden om de organische positie binnen Google te manipuleren. Waak worden deze weergegeven in een lijst of groep en is dit niet relevant met de rest van de content. Goede voorbeelden zijn:
• Lijsten met diensten of artikelen zonder enige relevantie
• Het opsommen van steden en regio’s om uitsluitend zoveel mogelijk vertoningen te genereren
• Zoekwoorden of zinnen zo vaak herhalen dat het niet natuurlijk leest. Bijvoorbeeld:
De rookmelder van Sinsi is de beste rookmelder van nu omdat de rookmelder is uitgerust met allerlei nieuwe technieken. Op verschillende testen over rookmelders komt de rookmelder van Sinsi dan ook als beste uit de bus. Wanneer je dus een rookmelder van Sinsi aanschaft ben je verzekerd van een goede rookmelder. Koop de rookmelder van Sinsi vandaag nog!
Link SPAM
Een belangrijke factor bij het bepalen van de relevantie van webpagina’s zijn de links die verwijzen naar jouw domein. Alle links die zijn gemaakt om de positionering in de SERP te beïnvloeden worden beschouwd als linkspam. Enkele voorbeelden van linkspam:
• Het kopen of verkopen van links voor ranking doeleinden. Dus iedere vorm van betaling van een link zoals een rechtstreekse vergoeding, goederen of diensten uitwisselen voor een link of iemand op een andere manier belonen voor het plaatsen van een link.
• Overduidelijke linkuitwisselingen (‘Als jij naar mij linkt, dan link ik naar jou’) of andere vormen van partner linkuitwisselingen. Dit wordt crosslinking genoemd.
• Geautomatiseerde programma’s of platformen gebruiken (linking farms) om zoveel mogelijk backlinks te verzamelen
• Een vereiste koppeling als onderdeel van bijvoorbeeld servicevoorwaarden zonder de eigenaar van deze content de gelegenheid te stellen de link te kwalificeren
• Niet-geblokkeerde teksten en links in advertenties die de rangschikking beïnvloeden
• Advertenties, artikelen of blogberichten waarbij betaling wordt ontvangen wanneer er op een link wordt geklikt.
• Sitekoppelingen voor mappen of bladwijzers van lage kwaliteit
• Widgets met verborgen links met veel zoekwoorden die over verschillende sites zijn verspreid
• Links in de voetteksten of sjablonen van verschillende sites
• Reacties in forums die links bevatten
Het is wel toegestaan om links te kopen of verkopen zolang deze maar zijn gekwalificeerd met een tag als rel=”nofollow” of rel=”sponsored” wat een zoekmachine duidelijk maakt dat deze link niet door Google mag worden geïndexeerd voor de ranking.

Machine-gegenereerd verkeer
Het inzetten van machine-gegenereerd verkeer zijn automatische tools om zoekmachines te beïnvloeden op verschillende manieren en een absolute schending van het beleid van Google. Voorbeelden zijn:
• Geautomatiseerde zoekopdrachten verzenden naar Google
• Het scrapen van de zoekresultaten van voor eigen analyses of andere vormen van geautomatiseerde toegang zonder uitdrukkelijke toestemming van Google
Malware en kwaadaardig gedrag
Google controleert regelmatig websites om in de gaten te houden of er malware of ongewenste software wordt gebruikt die de gebruikerservaring negatief beïnvloedt
• Onder malware wordt verstaan elke vorm van software die is ontworpen om een computer of een mobiel apparaat te beschadigen. Malware vertoont kwaadaardig gedrag zoals het zonder toestemming installeren van software bij de gebruiker. Vaak is hier dan sprake van schadelijke software zoals virussen. Een eigenaar van deze website is soms helemaal niet op de hoogte dat deze downloadbare bestanden als malware worden beschouwd, het is dus zaak hier een expert naar te laten kijken.
• Onder ongewenste software wordt verstaan een bestand die bij uitvoering misleidend of onverwachte handelingen verricht. Een voorbeeld is software die je startpagina overzetten, apps automatisch downloaden op je smartphone of persoonlijke informatie verzameld en doorstuurt zonder dat vooraf kenbaar te maken.
• Webdevelopers moeten goed op de hoogte zijn van de richtlijnen van Google
Geschraapte content
Soms wordt er gebruik gemaakt van een techniek die “scraping” wordt genoemd. Er wordt dan content automatisch van websites met een hoge autoriteit “geschraapt” en dit biedt een bezoeker geen toegevoegde waarde. In sommige gevallen is er ook sprake van inbreuk van auteursrecht. Wanneer een eigenaar van een website hun content op een andere website tegenkomt kan deze een verwijderingsverzoek indienen en wanneer er maar genoeg verzoeken worden ingediend door verschillende website eigenaren zal dit tot penalty’s leiden. Voorbeelden van scraping zijn:
• Websites die content van andere sites kopiëren en opnieuw publiceren zonder er zelf originele content aan toe te voegen
• Websites die content van andere sites kopiëren en deze alleen een beetje herschrijven of dit zelfs volledig geautomatiseerd doen en vervolgens opnieuw publiceren
• Websites die hoofdzakelijk andere vormen van content zoals afbeeldingen en video’s publiceren van andere websites en hierdoor geen meerwaarde heeft voor bezoekers
Automatisch gegenereerde content
Met automatisch gegenereerde content wordt verstaan iedere content die wordt gepubliceerd zonder zelf iets origineels aan toe te voegen. De content wordt alleen geplaatst om vertoningen te genereren en de zoekmachines te manipuleren. Voor een bezoeker is hier geen enkel voordeel te behalen.
Voorbeelden van automatisch gegenereerde content:
• Een totaal irrelevante tekst maar deze staat vol met zoekwoorden die voor de website eigenaar wel een (commercieel) belang dienen
• Automatisch vertaalde teksten zonder menselijke correcties waardoor er onnatuurlijke teksten zijn ontstaan
• Automatische teksten van lage kwaliteiten die leiden tot een slechte UX
• Iedere vorm van tekst gecreëerd met AI tools zoals het inmiddels bekende ChatGPT
• Content automatisch ontworpen met scraping software
• Het combineren van content van verschillende websites zonder enige relevantie of uniek materiaal
Dunne Affiliatie pagina’s

• Met dunne affiliatie pagina’s worden pagina’s bedoelt waarop producten of diensten van andere websites zijn gekopieerd en geplaatst zonder zelf unieke content aan toe te voegen.
• Affiliatie pagina’s worden als dun geïndexeerd zal ze onderdeel uitmaken van een groot netwerk wat als enige doel heeft zoveel mogelijk affiliatie-links te plaatsen zonder extra en unieke content aan toe te voegen. Wanneer bezoekers in zoekmachines overal dezelfde links aan zal treffen biedt dit geen enkele meerwaarde dus zal Google deze pagina’s uit hun zoekresultaten verwijderen.
• Google heeft geen moeite met affiliatie pagina’s zolang deze maar een duidelijke meerwaarde biedt aan een bezoeker. Een goed voorbeeld is een uitgebreide persoonlijke ervaring van een product al dan niet ondersteund met eigen afbeeldingen of video’s.
Conclusie
Wanneer een website herhaaldelijk het SPAM-beleid van Google schendt is de kans groot dat dit consequenties heeft. Het heeft geen zin om websites of content te blijven publiceren die dit beleid schendt of andere methoden te gebruiken. Het Penquin algoritme is steeds beter in staat dit te herkennen en het leidt alleen tot schade aan jezelf (verspilde tijd, moeite en geld) en schade aan de bezoekers.
Waar Google tegenwoordig steeds meer de focus op legt is het herkennen van oplichting en fraude. Het is genoeg in het nieuws geweest dat dubieuze slotenmakers bovenaan stonden in Google Ads en torenhoge tarieven vroegen aan mensen die zichzelf hadden buitengesloten en in paniek zo snel mogelijk hulp zochten.

Gelukkig heeft Google actie ondernomen en wordt het voor dit soort malafide bedrijven steeds moeilijker zo te werk te gaan. De focus licht bij dit soort zaken het meest bij:
• Bedrijven die zich officieel voordoen via bedrieglijke sites om bezoekers geld afhandig te maken
• Het opzettelijk publiceren van onjuiste informatie over een bedrijf of dienst
• Gebruikers naar hun website leiden onder valse voorwendselen
• Misleidende websites die de suggestie wekken een goede service te verlenen maar dit niet bieden
• Valse of onjuiste contactgegevens. Het ontbreken van contactgegevens is geen negatief element voor Google, maar ik kan het niet aanbevelen. Er zijn genoeg onderzoeken die aantonen dat dit leidt tot een flinke daling in vertrouwen. En terecht.
Eigenlijk volstaat het je simpelweg bezig te houden met het maken van een zo goed mogelijke website die het meeste waarde biedt aan jouw bezoeker. Iemand die met je meekijkt of je geen fouten maakt (al dan niet bewust) is aan te bevelen om te voorkomen dat je op een dag penalty’s krijgt en je geen flauw idee hebt waar deze vandaan komen. Heb je vragen of kun je advies gebruiken? Neem contact op!


